-

【数学の疑問】マイナス×マイナス=プラスの納得できる考え方を徹底解説!
-

【数学の疑問】確率は掛け算で求める根本的な理由をストーリーで徹底解説!
-
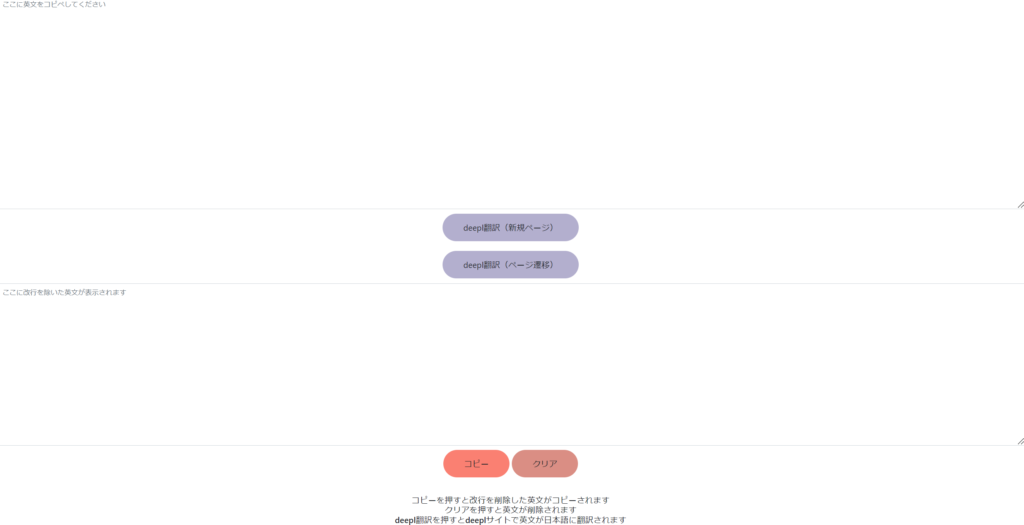
論文をdeeplで翻訳しようとして改行が邪魔だった時に便利なウェブアプリを作ってみた!効率的に論文を読もう!
-

独学で統計検定データサイエンス発展に合格!必要最低限どれくらいの知識があれば合格できるのかを解説!
-

データ分析・分類問題において分類精度が高いだけで良いのか?AIに分類根拠を説明させることはできる?WEBGPT・LaMDAを活用できないか考えてみた
-

【LaMDA】最大1370億のパラメータを持ち1.56兆語のデータで事前学習された対話に特化した自然言語モデル!論文の感想+LaMDAの活用方法を考えてみた
-

【WEBGPT】人間のようにウェブから回答を探してくるGPT-3のファインチューニングモデル!GPT-3をファインチューニングしたら何ができるのか?
-

【PyTorch】手書き文字判別においてニューラルネットワークはどうあるべきか?精度99%を目指して活性化関数などを変更してみた
-

【PyTorch】ベクトルを操作する代表的な関数を解説!view, reshape, transpose, unsqueeze, matmul, einsumなどを使えるようになろう!
-

【Python】seleniumでfind_element_by_class_nameが使えない時の対処法を紹介!開発者ツールからclass=の部分を取ってきてfind_element_by_class_nameに突っ込んだのにエラーが出る方必見!
















