【Stable Diffusion】Dream Studioを試そう!スマホからも利用可能!画像生成サービスを紹介!

テキストから画像を生成するサービス「Dream Studio」が新たに登場しました。
これまでも「Midjourney」や「Dream by WOMBO」など画像生成サービスはありましたが、これらのモデルは公開されていません。


そのような状況の中でモデルをオープンに公開したのが、今回紹介するAIになります。
では、そんなAIをの使い方について見ていきましょう。
はじめに
Stable Diffusionを試す方法は以下の3つになります。
- Hugging faceから試す(スマホでも可)
- DreamStudioのベータ版を試す(スマホでも可)
- Google Colaboratory(無料枠)を使って試す
それぞれ説明していきます。
Hugging faceから試す
Hugging faceは、機械学習に用いられるモデルやデータセットなどを公開しています。
例えば次のようなモデルを公開しています。

また、ウェブアプリを公開することができます。
今回のAIもそこから利用できるようになっているので、使い方を見ていきましょう。
まずは、下のボタンからサイトにアクセスします。
アクセスすると次のようなページに飛びます。
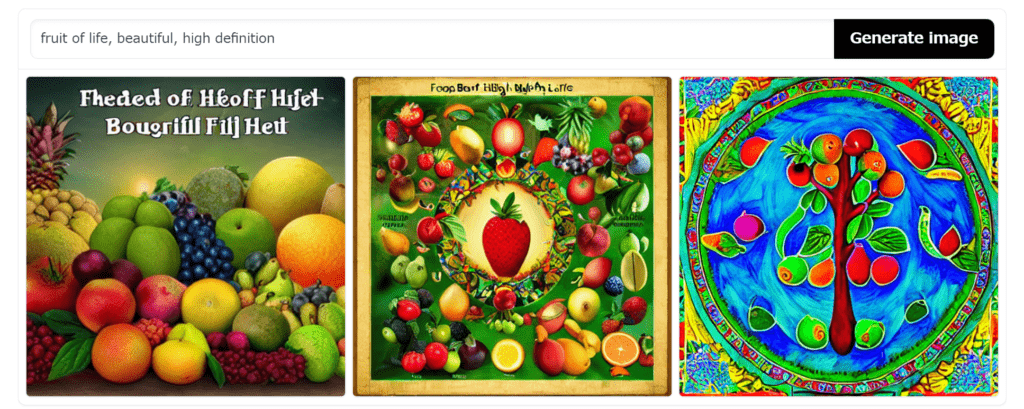
「Enter your prompt」のところに生成したい画像の説明文を入力してから「Generate image」を押します。

数十秒待つと次のような画像が生成されます。
DreamStudioのベータ版を試す
まずは、下のボタンからβ版のサイトにアクセスします。
アクセスすると次のようなページに飛びます。
それぞれの方法で登録してからログインしましょう。
私は、「Continue with Google」から登録しました。
ログインすると次のようなページに飛びます。
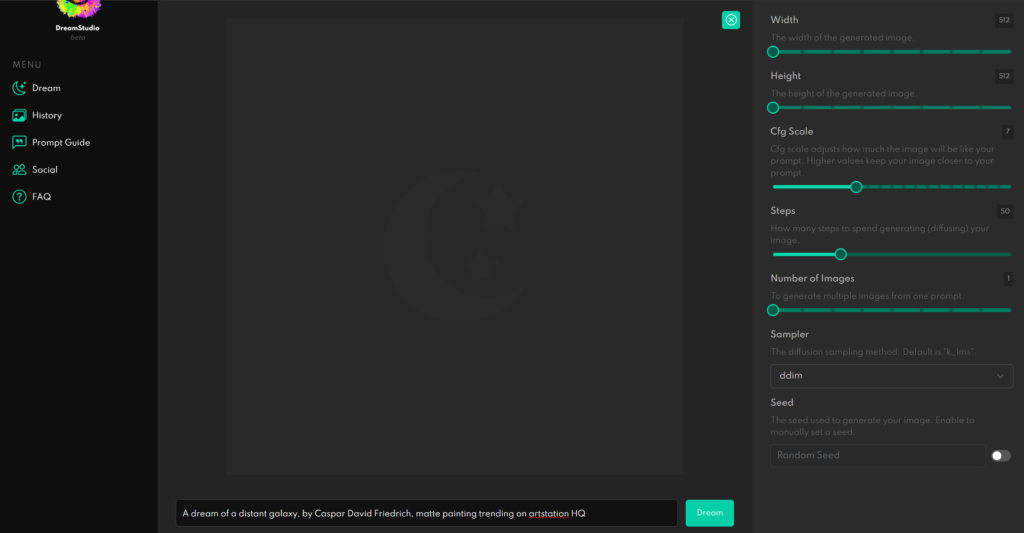
中央のテキストを消して、その部分に生成したい画像の説明を入力してから「Dream」と書かれた緑のボタンを押すと画像が生成されます。

Menuの説明
ページの左側にある次のようなMenuの説明を見ていきます。
- Dream
-
ホーム画面に戻ります。
- History
-
これまで生成した画像を閲覧できます。
- Prompt Guide
-
どんなテキストを入力するべきかのガイドが書かれています。
- Social
-
作成者について書かれています。
- FAQ
-
簡単な質問に対する返答が書かれています。
生成画像の詳細設定
ページ右側の次の項目では、生成する画像の詳細を設定できます。
それぞれの意味の説明を見ていきます。
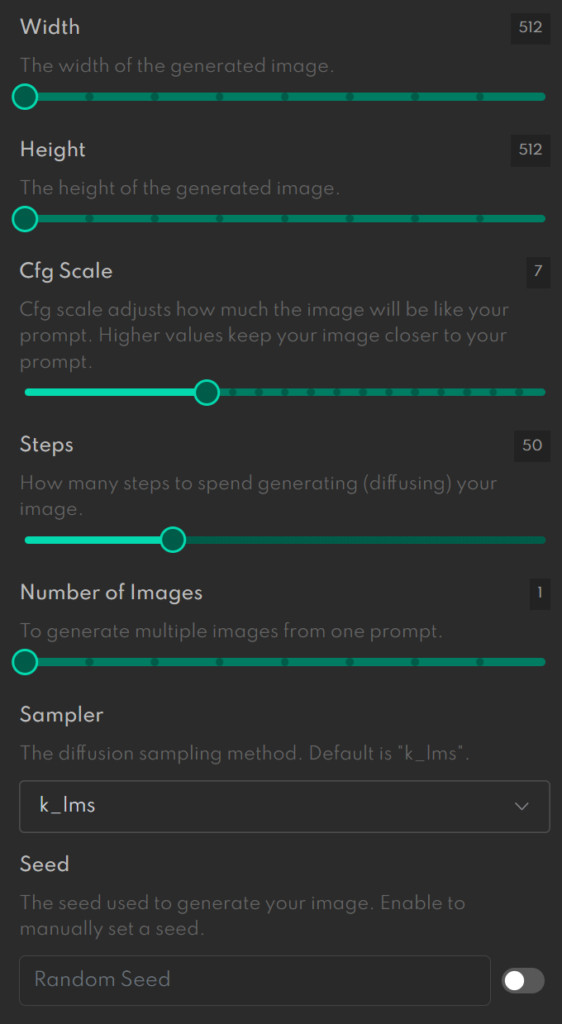
- Width
-
生成する画像の幅を指定できます。
- Height
-
生成する画像の高さを指定できます。
- Cfg Scale
-
テキストが与える影響度合いを設定できます。
- Steps
-
画像の生成に何ステップかけるかを設定できます。
- Number of Images
-
生成する画像の数を設定できます。
- Sampler
-
拡散サンプリング方式を指定できます。
- Seed
-
設定すると同じテキストなら同じ画像が生成されます。
Google Colaboratory(無料枠)を使って試す
pythonを使って画像生成するためには、GPUを使える環境が必要です。
ということで、無料でGPUが使えるGoogle Colaboratoryを利用して試していきます。
一応、スマホでもできるとは思いますが、やりにくそうですね。
実行環境
Google Colablatory(無料枠)
GPU:Tesla T4が割り当てられました。
事前に必要なもの
コードを実行する前に必要なものは以下の通りです。
- Huggingfaceに登録してアクセストークンを発行
- Google Colablatoryに登録
hugging faceの登録はこちらにアクセスして「Sign Up」から登録を行ってください。
ログイン後、右上のアイコンから「Settings」→「Access Tokens」をクリックしてトークンを取得してください。
Google Colablatoryについては、こちらからログインしてください。
コードの説明
では、画像生成するまでのコードを見ていきます。順番にコードを実行すると画像が生成できます。
ランタイムをGPUに切り替えてから次のコードを実行してください。
!pip install --upgrade diffusers transformers scipy必要なライブラリがインストールされます。
!huggingface-cli login上記のコードを実行すると、次のようなテキストが出てきます。

Tokenの右のエリアに事前に準備してもらったアクセストークンを入力します。
成功するとToken: Login successful Your token has been saved to /root/.huggingface/tokenと出てくると思います。
また、!git config --global credential.helper storeをもし必要なら実行しようねという感じのテキストも出てくる方は、その文に従って実行しましょう。
!git config --global credential.helper storeちなみに、上記のコードを実行しないとモデルを読み込んだ時にHTTPError: 403 Client Error: Forbidden for urlがでてしまいます。
続いて、モデルの読み込みを行います。
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True) 上記の部分で他のバージョンに変えることができます。今回は、精度を少し落とす代わりに生成する時間を短縮しています。
次のコードを実行しないと、"LayerNormKernelImpl" not implemented for 'Half'というエラーが出るので実行しておきましょう。
pipe = pipe.to("cuda")ここまで進めることができれば、後は画像を生成するだけです。
import torch
generator = torch.Generator("cuda").manual_seed(1024)
prompt = "a photo of an astronaut riding a horse"
with torch.autocast("cuda"):
image = pipe(prompt, generator=generator)["sample"][0]
# 画像を保存する
image.save(f"a_photo_of_an_astronaut_riding_a_horse.png")生成した画像はこちらです。15秒ほどで生成できました。

画像生成時のオプションの一部
画像を生成するコードを少し変更するだけでサイズなどの変更が可能です。
サイズを変更する
prompt = "a photograph of an astronaut riding a horse"
with torch.autocast("cuda"):
image = pipe(prompt, height=512, width=768)["sample"][0]
image
複数画像を生成する
from PIL import Image
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return gridnum_cols = 3
num_rows = 1
prompt = ["a photograph of an astronaut riding a horse"] * num_cols
all_images = []
for i in range(num_rows):
with autocast("cuda"):
images = pipe(prompt)["sample"]
all_images.extend(images)
grid = image_grid(all_images, rows=num_rows, cols=num_cols)
grid
step数を調整する
import torch
generator = torch.Generator("cuda").manual_seed(1025)
with autocast("cuda"):
image = pipe(prompt, num_inference_steps=15, generator=generator)["sample"][0]
imageデフォルトはnum_inference_steps=50なので15だと荒くなります。その代わり生成速度は短縮されます。

色々と生成してみた
使い方について紹介したところで色々と試してみました。
日本語で画像生成
入力として日本語をいい感じに処理してくれるのか気になったので入力してみました。
アニメ風の少女

日本語で意味を表現できていそうですね。
木から落ちる猿

と思ったら猿を猫と間違えていますね。
木から落ちる猫
では、猫はどうなるのか?ということで猫も生成してみました。

猫だけ不自然に合成されたような画像ですね。
とりあえず、猫は猫のようです。

英語で画像生成
日本語でもある程度生成できることが分かりましたが、やはり英語で生成した方がいいと思うので英語で生成していきます。
ape falling from a tree

猿らしき生物が木から落ちていますね。
The Giant Guardian, HD, Creative Artists, matte painting trending on artstation HQ

ゲームに出てきそうですね。
a photo of Good looking Japanese male in his 20s, HD, HQ

どこかにはいそうな感じですね。
最後に
今回は、話題のStable Diffusionについて使い方を解説していきました。
これまでのサービスとは異なりモデルをオープンにしているのはかなり社会的な意義が大きいと思います。
権利的な問題であったり、生成される画像の倫理的な問題であったり色々ありますが、今後もそのあたりを注視ながら楽しみたいですね。

コメント