【LaMDA】最大1370億のパラメータを持ち1.56兆語のデータで事前学習された対話に特化した自然言語モデル!論文の感想+LaMDAの活用方法を考えてみた

LaMDAとは
LaMDAは、テキストコーパスの次のトークンを予測するために事前に学習された言語モデルです。
また、対話データのみで学習させた従来の対話モデルとは異なり、公開対話データと他の公開Web文書から作成したデータセットでLaMDAを事前学習させているので、LaMDAはファインチューニング前の一般的な言語モデルとして使用することもできます。特徴としては、アザラシになりきって会話ができたり、エベレスト山になりきって会話ができたりします。
学習方法、評価指標や学習データなどについては軽く触れるだけにします。詳しくは論文を読んでください。流れとしては、対話データを多く含んだデータセットで事前学習モデルを作成した後、TSと呼ばれる独自のツールセットにクエリを送って正しい回答ができるようにファインチューニングします。
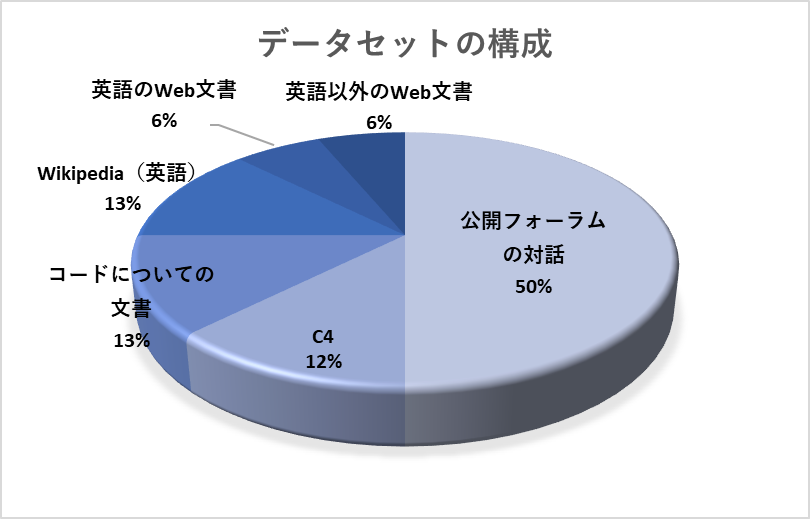
事前学習のためのデータセット
事前学習におけるデータセットは以下のような構成になっています。
評価指標
大枠としては、Quality(品質)・Safety(安全性)・Groundedness(根拠度)・Helpfulness(有用性)・Role consistency(役割の一貫性)の評価指標があります。
様々な面から評価することでより人間らしい回答ができるように学習されています。
情報検索システムを利用するためのファインチューニング
LaMDAのような言語モデルは、一見もっともらしいが、既知の外部ソースによって確立された事実と矛盾する出力を生成しがちです。
例えば、ニュース記事の冒頭のような入力が与えられると、大規模な言語モデルは、それっぽい感じの自信に満ちた出力を続けます。しかし、このような内容は、信頼できる外部文献との関連性がなく、それっぽい内容を模倣しているに過ぎません。
上記のような問題に対応するために、外部の知識資源やツールのセットを参照しながら学習する方法が提案されています。同じような機能をもつ言語モデル(WEBGPT)も存在するので、このような方法はこれからも増えていくかもしれません。
The toolset (TS)とは
上記の理由からLaMDAのファインチューニングのためにTSと呼ばれるツールセットが作成されています。このTSは情報検索システム、計算機、翻訳機で構成されており、一つの文字列を入力とし、一つまたは複数の文字列のリストを出力します。
評価結果
評価結果については、論文を読んでみてください。事前学習モデルとファインチューニングモデルの比較やモデルサイズによる比較などがなされています。
LaMDAが可能な会話
LaMDAは根拠を元に会話を進めることはもちろんのこと、金融などについての無責任な回答をしてはいけないような質問に関しては、他の質問に変えてもらうように応答をしてきます。また、TSを用いた計算や翻訳もしてくれるためツールを用いない言語モデルに比べてかなり強力な会話が可能になっています。他にもまとめると次のような会話が可能です。
- 無責任な回答をしないように会話する
- 映画の専門家として答えてくれる
- エベレスト山になりきって答えてくれる
- PythonやC++について答えてくれる
- ある程度状況を理解して回答してくれる
- 広いトピックについても答えてくれる
論文中にはいくつかの会話例があります。面白いので是非見てみてください。
論文を読んで
LaMDAに関する論文を読んでまず思ったのは、日本語バージョンがあればいいのにということです。このような大規模なモデルは、学習データの量はもちろんのこと質的にも高いものが求められますが、日本語の大規模対話データセットとなると企業だったとしてもなかなか集められないのが現状だと思います。ましてや個人ともなると計算リソースもないので何もできません。LaMDAについては最大サイズである1370億パラメータを持つモデルで1024個ものTPU-v3チップを使っても事前学習に57.7日費やしています。大きな企業においてもこれだけの時間がかかっており、さらにファインチューニングの学習データセットも作成するとなると何か月必要なのか想像するだけで嫌になってきます。また、それに伴って費用の方もかなりかかるので、尚更モデル作成のハードルは高くなっています。できるとすれば、より小さなモデルで実現することですが、それでも学習データを用意するハードルは越えなければいけないので難しそうです。
また言語モデルがどのような出力するのかの方向性を決めるのは、やはり人間次第なのだと感じました。LaMDAに関しては、それぞれの指標を満たしたデータを使ってファインチューニングしたモデルは、その指標において精度が向上しています。このことからファインチューニングにおける学習データはとても重要であると言えます。つまり、学習データを差別的・攻撃的なデータにすることもできてしまいます。例えば、世論誘導するために学習したりわざとフェイクニュースを根拠として示すように学習したりすることもできてしまいます。学習データによってはこのように悪用される危険性を持つモデルは、今後もたくさん出てくるのだろうと思います。LaMDAにおけるこのあたりの話では、うまく指標を設定して学習データを用意しています。
次に、ものになりきって会話をすることができるという点はかなり驚きました。論文中ではアザラシになりきって回答していたり、生物以外のエベレスト山になりきって回答していたりなどとてもおもしろい会話が見れます。自分でもペルソナを設定して会話してみたいです。また、これも学習データによってしっかり回答できるか決まるのでどのようなデータを学習させるのかといった重要性を感じます。
LaMDAの活用方法
日本語版の事前学習モデルとしてのLaMDAがあると仮定した時に、実現できるのではないかと考えられる活用方法を紹介します。
企業の製品の専門家としてのペルソナを与えて応答ボットにする
企業として活用する場合は、一つのモデルを用いることであらゆる事柄に精通した専門家を作れるかもしれません。例えば、企業の製品を熟知したAIを作って商品紹介をさせた方がよりクリエイティブに宣伝できる可能性があります。他にも企業の製品になりきって会話をするというのも話題性としては十分だと思います。
ゲームに組み込む
LaMDAは様々なゲームに組み込むことができると思います。例えば、RPGであれば、それぞれのキャラクターにどのような人物かの情報を与えるだけで会話ができるようになります。プレイヤーの会話でストーリーが変わっていくゲームとかもありますし面白そうです。
最後に
今回はLaMDAについていろいろとみていきました。言語モデルがより言語の深いところまで理解できるようになってきた中で、それは悪用される恐れがあるということも表していることは注意するべきであると感じます。例えば、TwitterなどのSNSにおいて特定の思想をマジョリティであるかのように見せることやフェイクニュースをいかにも事実であるかのように広めることもできてしまいます。私たちとしては、このような技術があることを認識してこれらの可能性を考えて情報を仕入れていく必要があると思います。
ここまで読んでいただきありがとうございました。


コメント