【PyTorch】手書き文字判別においてニューラルネットワークはどうあるべきか?精度99%を目指して活性化関数などを変更してみた

今回は比較的学習が早くできるMNISTデータセットを用いてニューラルネットワークを学んでいきたいと思います。また、活性化関数や層の数を増やすことで精度がどのように変化するのかを見ていきます。
精度99%を達成したコード
はじめに、精度99%を達成したコードの説明です。
必要なモジュールをインストールします。
import torch
import torch.nn as nn
import torch.nn.functional as f
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt今回使用するデータをセットします。
# train用データ
train_loader = DataLoader(
datasets.MNIST('./',
train=True,
download=True,
transform=transforms.Compose([
transforms.ToTensor()
])),
batch_size=batch_size,
shuffle=True
)
# eval用データ
test_loader = DataLoader(
datasets.MNIST('./',
train=False,
transform=transforms.Compose([
transforms.ToTensor()
])),
batch_size=batch_size,
shuffle=True)
data_loader_dict = {'train': train_loader, 'test': test_loader}モデルを作成します。よくある畳み込みニューラルネットワークです。活性化関数はGELUを採用しています。
class Net(nn.Module):
def __init__(self):
super().__init__()
self.gelu = nn.GELU()
self.pool = nn.MaxPool2d(2, stride=2)
self.conv1 = nn.Conv2d(1,28,3)
self.conv2 = nn.Conv2d(28,32,3)
self.fc1 = nn.Linear(32*5*5, 100)
self.fc2 = nn.Linear(100, 10)
def forward(self, x):
x = self.conv1(x)
x = self.gelu(x)
x = self.pool(x)
x = self.conv2(x)
x = self.gelu(x)
x = self.pool(x)
x = x.reshape(x.size()[0], -1)
x = self.fc1(x)
x = self.gelu(x)
x = self.fc2(x)
return f.log_softmax(x, dim=1)モデルを学習・検証します。
epochs = 20
batch_size = 200
train_loss_list = []
test_loss_list = []
test_acc_list = []
net = Net()
optimizer = torch.optim.AdamW(params=net.parameters(), lr=0.005) # 最適化アルゴリズムを選択
for epoch in range(epochs):
""" Training """
loss = None
net.train()
for i, (data, target) in enumerate(data_loader_dict['train']):
optimizer.zero_grad()
output = net(data)
loss = f.nll_loss(output, target)
loss.backward()
optimizer.step()
print("\rTraining log: {0} epoch ({1} / {2}). Loss: {3}%".format(epoch+1, (i+1)*batch_size, len(train_loader)*batch_size, loss.item()), end="")
train_loss_list.append(loss)
""" eval """
net.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in data_loader_dict['test']:
output = net(data)
test_loss += f.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= 10000
print("")
print('Test loss (avg): {0}, Accuracy: {1}'.format(test_loss, correct / 10000), sep="")
test_loss_list.append(test_loss)
test_acc_list.append(correct / 10000)学習結果
結果をプロットするコードです。
# 結果の出力と描画
print("test_acc", test_acc_list)
plt.figure()
plt.plot(range(1, epochs+1), train_loss_list, label='train_loss')
plt.plot(range(1, epochs+1), test_loss_list, label='test_loss')
plt.xlabel('epoch')
plt.legend()
plt.figure()
plt.plot(range(1, epochs+1), test_acc_list)
plt.title('test accuracy')
plt.xlabel('epoch')結果はこちらです。
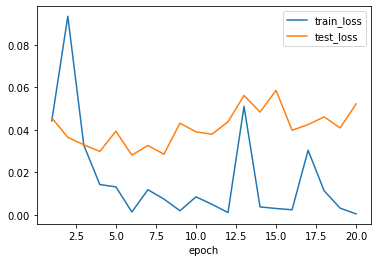
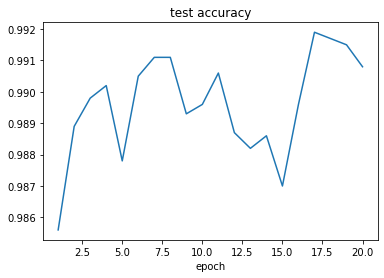
試行錯誤
上記の結果に至るまでに、様々な活性化関数や層の数を試してみました。
はじめは、畳み込みニューラルネットワークを使わずにどこまでいけるのかを試していましたが、精度98%が限界のようでした。層の数を増やしても逆に精度が悪くなったり、当たり前のように学習時間が増えたりするので、手書き文字判別のような単純な分類においては層の数はあまり増やさない方が良いのではないかと思いました。
最適化アルゴリズムに関しては、畳み込みの有無に関わらず、AdamWとAdamで同じような結果になりました。他のアルゴリズムも試しましたが、あまり良い結果にはなりませんでした。
活性化関数に関しては、sigmoid, tanh, ReLUなどありますが、自然言語処理分野に使われているGELUを使ってみました。精度は、tanh<sigmoid<GELU<ReLUの順で良かったです。畳み込みニューラルネットワークでは、GELUとReLUを使うと精度が99%を超えました。
最後に
今回は、ニューラルネットワークの導入においてよく使われている手書き文字判別を試していきました。精度を求めてモデルを構築していくのは、とても勉強になるのではないでしょうか。手軽にコードを動かせるので、暇な時などに試してみるのも面白いと思います。
ここまで読んでいただきありがとうございました。

コメント