【Pytorch】nn.Linearの引数・ソースコードを徹底解説!

torch.nn.Linearは基本的な全結合層です。あのtransformerの内部にも全結合層は登場します。
ドキュメント:
nn.Linear — PyTorch 2.0 documentation
torch.nn.functional.linear — PyTorch 2.0 documentation
nn.functional.linearもありますが、基本的にはあまり違いはないので今回はnn.Linearの解説となります。
nn.Moduleとnn.functionalの違いについてはこちらをご覧ください。

全結合層は言語モデルなどのアーキテクチャにおいて重要な役割を担っています。
言語モデルに興味のある方はこちらもご覧ください。

全結合層を理解しよう
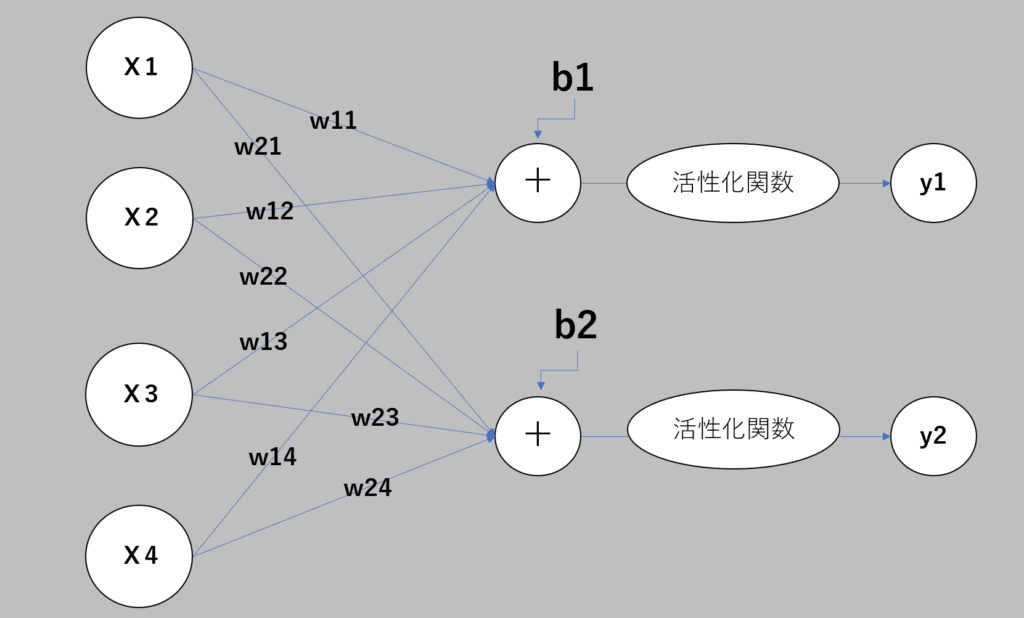
nn.Linearにおける全結合層は、上図の活性化関数よりも左側の構造のことを言います。
Xは入力、Wは重み付けのパラメータ、bはバイアスを表します。
活性化関数をf()で表すと、y1=f {(x1×w11 + x2×w12 + x3×w13 + x4×w14) + b1}となります。
W, bは学習可能なパラメータ!
nn.Linearの引数・コード例
import torch
import torch.nn as nn
# linearインスタンスを生成する
m = nn.Linear(2, 3)
# 平均0、分散1の正規分布からの乱数で埋め尽くされたテンソルを生成する
input = torch.randn(4, 2)
# inputを入力してoutputとして出力する
output = m(input)
print(output.size())
# torch.Size([4, 3])各行のコードの説明はメモを見てもらうとして、Pytorchではこんなにも少ないコードで全結合層を実装することができます。
引数は、nn.linear(in_features, out_features, bias=True)となっています。
各入力サンプルのサイズのこと
各出力サンプルのサイズのこと
各層がバイアスを学習するかを決める
False にセットされた場合、レイヤーは加算バイアスを学習しない。デフォルトは True
nn.linearのソースコードの解説
では、nn.linearのソースコードについて解説していきます。
nn.Linearはnn.Moduleを継承しています。
そして、class内で定義されている関数が4つあるのでそれぞれ説明します。
__init__
__init__で定義したことはclassをインスタンス化した時に初期値として定義されます。
詳しくは、コメントを見てください。
def __init__(self, in_features: int, out_features: int, bias: bool = True,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(Linear, self).__init__()
# 入力の次元数を定義
self.in_features = in_features
# 出力の次元数を定義
self.out_features = out_features
# nn.Parameterを使って学習可能なパラメータをいれる箱を設定
# weightは先ほどの図のWのこと
self.weight = Parameter(torch.empty((out_features, in_features), **factory_kwargs))
if bias:
# biasがTrueなら学習可能なパラメータを入れる箱を設定
# biasは先ほどの図のbのこと
self.bias = Parameter(torch.empty(out_features, **factory_kwargs))
else:
# biasがFalseならbiasを設定しない
self.register_parameter('bias', None)
# weightとbiasの初期値を設定
self.reset_parameters()reset_parameters
reset_parametersでweightとbiasの初期値を設定します。
def reset_parameters(self) -> None:
# weightに[-1/sqrt(in_features), 1/sqrt(in_features)]の一様分布を設定
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0
# biasに[-1 / math.sqrt(fan_in), 1 / math.sqrt(fan_in)]の一様分布を設定
init.uniform_(self.bias, -bound, bound)weightの初期値はinit.kaiming_uniform_(self.weight, a=math.sqrt(5))で設定されています。
これは、 [-1/sqrt(in_features), 1/sqrt(in_features)]の一様分布で初期化したことと同じ意味になります。
このあたりの議論を知りたい方はこちらをご覧ください。
biasの初期値はinit.uniform_(self.bias, -bound, bound)で設定されています。
これは、 [-bound), bound]の一様分布で初期化したことと同じ意味になります。
boundは、1 / math.sqrt(fan_in) if fan_in > 0 else 0で定義されています。
fan_inはinit._calculate_fan_in_and_fan_out(self.weight)で設定されています。
init._calculate_fan_in_and_fan_outは、第一引数で与えられたテンソルのshapeによって許容できる次元を返します。
tensor.dim()が2の場合は、そのままの次元数が返ってきます。
forward
forwardでは、順伝播の処理を定義します。
def forward(self, input: Tensor) -> Tensor:
# 入力されたデータに線形変換を適用
return F.linear(input, self.weight, self.bias)F.linear(input, self.weight, self.bias)によって、入力されたデータに線形変換が適応されています。
extra_repr
モジュールの追加表現を設定します。 カスタマイズされた追加情報を表示するために必要です。
def extra_repr(self) -> str:
# 入力次元、出力次元、バイアスを返します。
return 'in_features={}, out_features={}, bias={}'.format(
self.in_features, self.out_features, self.bias is not None
)最後に
全結合層は、ニューラルネットワークにおいて基本となります。
データの流れを追うことで理解につながるので、ソースコードを見てデータがどのように操作されているのか分かるようになりましょう。





コメント