【Open Assistant】皆さんの協力が必要です!ChatGPTの亜種の作成に貢献しよう!

最近なにかと話題にあがるChatGPTですが、モデルそのものをダウンロードしたり、手持ちのデータセットでファインチューニングしたりはできません。今回紹介するOpen Assistantは、チャットベースの大規模言語モデルに誰でもアクセスできるようにすることを目的としたオープンソースのプロジェクトでChatGPTの代替を目指しています。つまり、このプロジェクトが成功すれば誰でもChatGPTの亜種を使うことができるようになります。そのため、学習などに必要な多言語で書かれたデータセットを集めており日本語のデータも収集中です。しかし、2023/2/13日時点で日本語は他の言語にデータセット数で劣っています。
そこで今回は、参加者が増えればいいなということでデータ収集用プラットホームへのログインの仕方、データセット作成時の注意点、データセット作成のタスクについてまとめました。
Open Assistantのドキュメントはこちらになります。プロジェクトのgithubはこちらです。Discordはこちらです。
・誰でも参加できます!
・たくさんの方の参加が日本語データセット構築への近道です。
・私も参加しています!
ログイン方法

Sign inをクリックしてください。
上記のようにメールアドレスが求められるので入力しましょう。または、Discordアカウントでもサインインできます。
ログインが完了すると、下のようなページに飛びます。
よく読んでから一番下のAcceptを押しましょう。

Acceptを押すと、タスクが表示されていると思います。
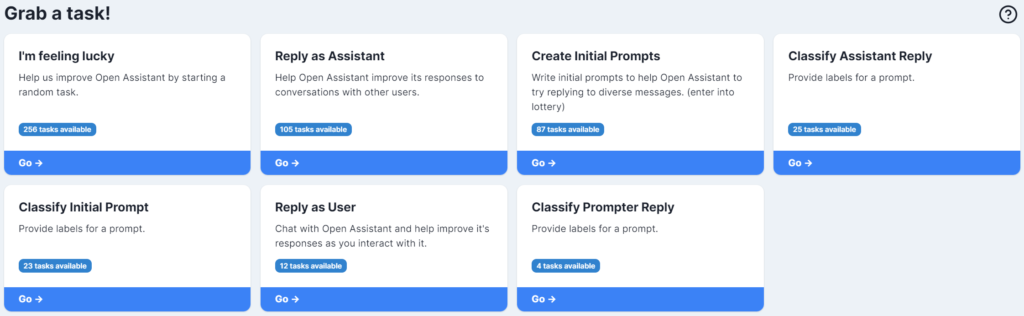
データセット作成時の注意点
タスクの一覧が出てきましたが、タスクを行う前に作成するデータについて知っておく必要があります。
以下、作成するデータの大まかな分類です。
- ユーザ側の文章(プロンプト)
- アシスタント側の文章(プロンプト)
- ユーザ側の文章(プロンプト)の評価(ラベル付け)
- アシスタント側の文章(プロンプト)の評価(ラベル付け)
これらは、学習データやデータの選別などで使われます。
また、作成する文章については、ユーザ側とアシスタント側で設定が異なる部分があります。
ここを間違えてしまう、または悪意を持った人がデータを作った場合、データセットが汚染されてしまいます。
ルールを守るデータ作成者を増やすためにもこれらのデータ作成時の注意点について説明します。
データ作成ガイドはこちらです。(色々と書いていますが、原文を読むのが一番だと思います。全てのガイドがかけている訳ではないので、適切な文章について調べて見てください。)
プロンプト作成時の注意点
ChatGPTを使用した回答を載せることは、利用規約に違反しています。
詳しくは、こちらのissueをご覧ください。
ユーザ側のプロンプト作成時の注意点
アシスタント側のプロンプト作成時の注意点
アシスタントの複数の回答を比較する時の注意点
2023/2/13時点では日本語データで比較するタスクはないですが、注意点を述べておきます。
タスク一覧
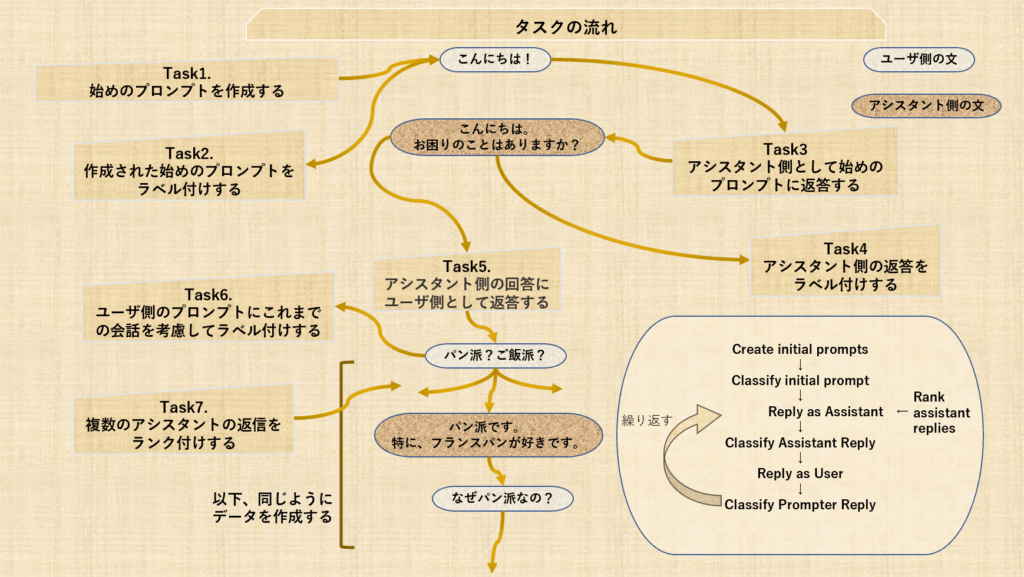
(2023年2月13日時点)次にこれらのタスクの説明をします。
自分のアカウントのタスク実施状況はこちらから確認できます。
(ちなみに、task1とかtask2とか勝手に名前つけてますが、どこからやってもいいと思います。)
TASK1 ユーザ側の始めのプロンプトを作成しよう


ユーザ側の最初のプロンプトを作成しよう!
TASK2 始めのプロンプトをラベル付けしよう


メッセージがスパムかどうかをラベル付けします。スパムなら「Yes」スパムではなければ「No」を選択してください。

日本語で書かれていなければ、このラベルを選択してください。
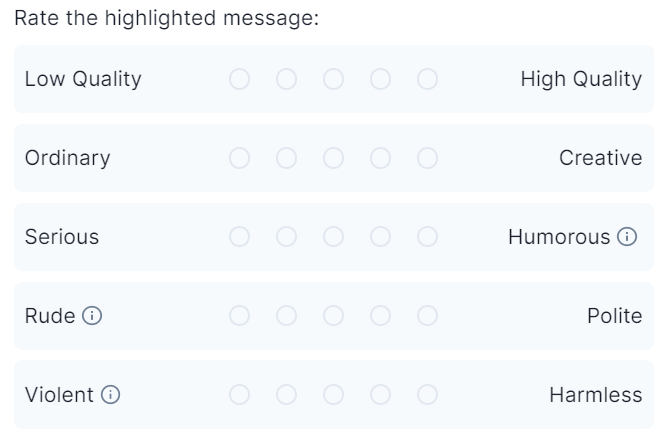
クオリティーが高いか低いかランクを付けてください。右にいくほど高クオリティです。
・メッセージがスパムなら「Yes」、スパムでないなら「No」をクリックしよう(必須)
・メッセージが「日本語でない」「適切ではない」「個人情報を含む」「偏見のある、誰かを傷つけている」「性的な内容を含む」場合にそれぞれクリックしよう(複数選択可能)
・「低クオリティか高クオリティか」「平凡かクリエイティブか」「真面目か(皮肉を含む)ユーモラスな内容か」「無礼か礼儀正しいか」「暴力的か無害か」をランク付けしよう(5段階)
TASK3 アシスタント側で返事をしよう

アシスタント側の適切な応答を入力しよう!
TASK4 アシスタント側の返答をラベル付けしよう
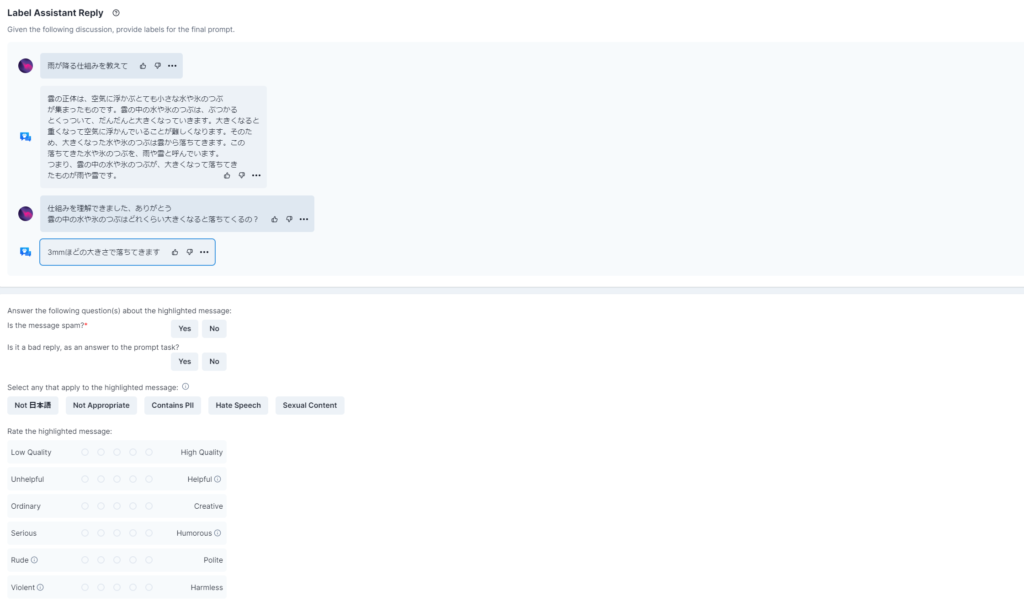

メッセージがスパムかどうか。スパムなら「Yes」スパムではなければ「No」を選択してください。

プロンプトタスクの回答として、悪い返事か。悪い返事なら「Yes」悪くない返事なら「No」を選択してください。
日本語で書かれていなければ、このラベルを選択してください。
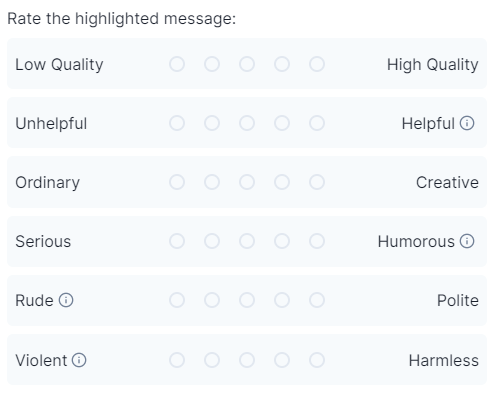
クオリティーが高いか低いかランクを付けてください。右にいくほど高クオリティです。
・メッセージがスパムなら「Yes」、スパムでないなら「No」をクリックしよう(必須)
・プロンプトタスクの回答として、悪い返事なら「Yes」悪くない返事なら「No」をクリックしよう
・メッセージが「日本語でない」「適切ではない」「個人情報を含む」「偏見のある、誰かを傷つけている」「性的な内容を含む」場合にそれぞれクリックしよう(複数選択可能)
・「低クオリティか高クオリティか」「役立たないか役立つか」「平凡かクリエイティブか」「真面目か(皮肉を含む)ユーモラスな内容か」「無礼か礼儀正しいか」「暴力的か無害か」をランク付けしよう(5段階)
TASK5 ユーザ側で返答しよう
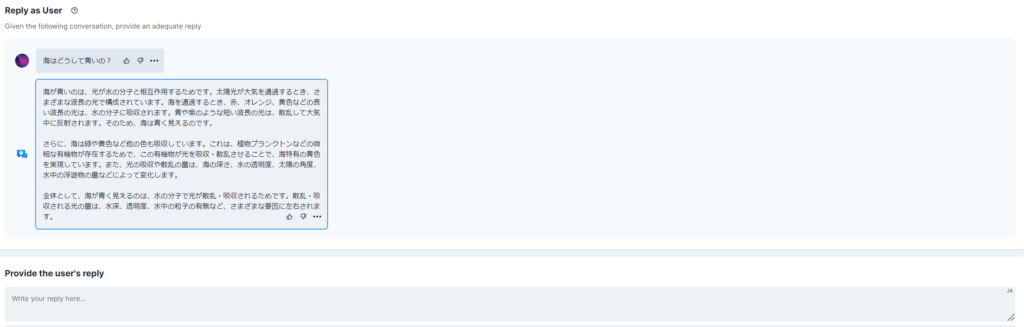
ユーザ側の適切な応答を入力しよう!
TASK6 ユーザ側のプロンプトにラベル付けしよう
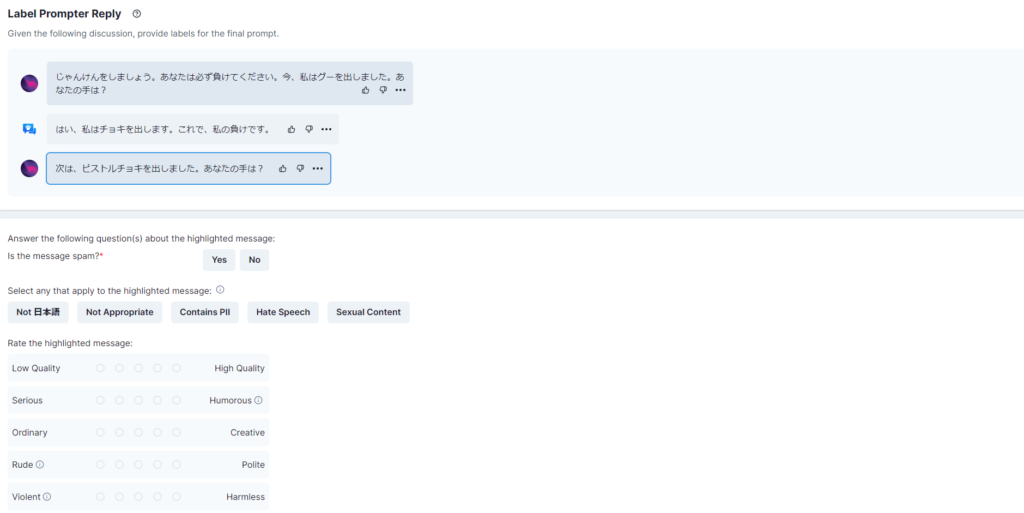
メッセージがスパムかどうか。スパムなら「Yes」スパムではなければ「No」を選択してください。
日本語で書かれていなければ、このラベルを選択してください。
クオリティーが高いか低いかランクを付けてください。右にいくほど高クオリティです。
・メッセージがスパムなら「Yes」、スパムでないなら「No」をクリックしよう(必須)
・メッセージが「日本語でない」「適切ではない」「個人情報を含む」「偏見のある、誰かを傷つけている」「性的な内容を含む」場合にそれぞれクリックしよう(複数選択可能)
・「低クオリティか高クオリティか」「平凡かクリエイティブか」「真面目か(皮肉を含む)ユーモラスな内容か」「無礼か礼儀正しいか」「暴力的か無害か」をランク付けしよう(5段階)
TASK7 アシスタントの返信をランク付けしよう
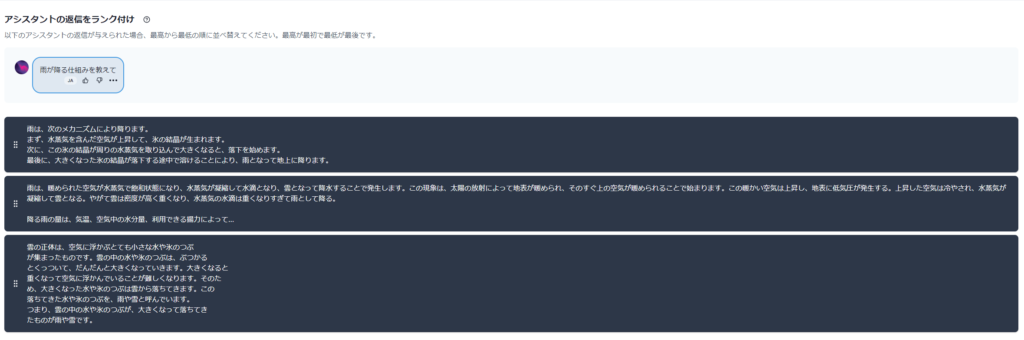
上の例では、黒色の部分を押しながら動かすとアシスタントの返信を並び替えることができます。
良いと思った順に上から並べてください。
ランダムタスク
割り当てられたタスクを行いましょう。
(もし、どのタスクをすればいいか分からない時は、これを選んでもいいかも。)
さらに貢献したい場合
データセットの作成だけではなく、さらに貢献したい場合は、GitHubにあるタスクを見てみましょう。方法については、このコントリビュートガイドを見てください。
言語ごとのメッセージ数を知りたい場合
言語ごとのメッセージ数を知りたい場合は、こちらのDiscordからDISCUSSION→data-updatesと進んで下さい。
最後に
今回は、Open Assistantについて紹介しました。
間違いがあればコメントお願いします。

コメント