RLHFの報酬モデル分析:OpenAssistantの報酬モデルが日本語応答で機能するか調査してみた

言語モデルにおける強化学習では、重要な要素の一つに報酬関数の設計があります。
この報酬関数は、生成されたテキストがどれほど「良い」かを評価する役割を果たします。
しかし、良いテキストとは何かを定義するのは難しいです。
文法的に正しいこと、意味的に意味をなすこと、話題に関連していること、人間が読んで楽しむことができることなど多くの要素が考慮されます。
この問題を解決する一つのアプローチが、報酬モデルの学習です。
具体的には、人間による評価(例えば、生成された応答がどれほど人間の好みに合っているか)を用いて、報酬モデルを学習します。このモデルは、新たな生成されたテキストに対して「人間の好みに合っているか」の評価を予測できます。
2023/07/20時点でHuggingFaceには「reward」や「rw-model」と調べると様々な報酬モデルが公開されていることが分かります。
そこで今回はOpenAssistantが公開している報酬モデルについて、日本語の文章をどれくらい正しく評価できるのか検証しました。
OpenAssistantが公開している報酬モデル
各データセットに対するValidation split accuracyです。
| Model | WebGPT | Summary | SytheticGPT | Anthropic RLHF |
|---|---|---|---|---|
| reward-model-deberta-v3-base | 59.07 | 66.84 | 99.85 | 54.51 |
| reward-model-deberta-v3-large | 61.13 | 72.23 | 99.94 | 55.62 |
| reward-model-deberta-v3-large-v2 | 61.57 | 71.47 | 99.88 | 69.25 |
| reward-model-electra-large-discriminator | 59.30 | 68.66 | 99.85 | 54.33 |
評価方法
こちらは、Anthropic/hh-rlhfを日本語訳されているデータセットです。
今回はこちらを使わせてもらいます。

chosen(選ばれた方)とrejected(拒否された方)で構成されています。
今回はそれぞれの文章を報酬モデルに入力して結果を比べ、chosenの方が高い報酬を与えられていれば正解として評価します。
翻訳の精度の問題は無視することにします。
4つのモデルで評価値を出すのに16時間くらいかかりました。
また、他にも色々と分析を行いました。
分析については、chatgptのCode Interpreterを使って行っています。
コードについても併記しておきます。
データの読み込みコード
import pandas as pd
# Load the spreadsheet
xls = pd.ExcelFile('/mnt/data/reward_model_evaluations.xlsx')
# Get the names of all sheets in the Excel file
sheet_names = xls.sheet_names
# ['reward-model-deberta-v3-base',
# 'reward-model-deberta-v3-large',
# 'reward-model-deberta-v3-large-v2',
# 'reward-model-electra-large-discriminator']
# Load the first sheet into a DataFrame
df1 = xls.parse(sheet_names[0])
# Load the second sheet into a DataFrame
df2 = xls.parse(sheet_names[1])
# Load the third sheet into a DataFrame
df3 = xls.parse(sheet_names[2])
# Load the fourth sheet into a DataFrame
df4 = xls.parse(sheet_names[3])chosen vs rejectedの結果
ではさっそく結果から見ていきましょう。
| モデル名 | 正解の割合 |
|---|---|
| reward-model-deberta-v3-base | 52.06% |
| reward-model-deberta-v3-large | 53.55% |
| reward-model-deberta-v3-large-v2 | 61.13% |
| reward-model-electra-large-discriminator | 49.44% |
reward-model-deberta-v3-large-v2の正解率が一番高いことが分かります。
他のモデルについては、ランダムにどっちがいいか判別するくらいの確率になってますね。
reward-model-electra-large-discriminatorに関してはそれよりも悪いわけですね。
これらのモデルの中ならreward-model-deberta-v3-large-v2が一番ましですが、やはり新たに日本語で学習した報酬モデルを構築するべきだと思います。
本末転倒のような感じがしますが、そもそもこの評価方法ではモデルの良さを測ることはできないような気がします。
例えば、chosenに-15, rejectedに-15.1を与えた時も正解になってしまいます。
他にも色々と不都合があるので今回の結果については、何かの目安として使ってもらえればと思います。
統計的な情報
では、その他のデータの特徴についても見ていきましょう。
コードはこちら
# Concatenate the statistics of all sheets
all_stats = pd.concat([df1_stats, df2_stats, df3_stats, df4_stats], keys=[df1['reward_model_name'].iloc[0], df2['reward_model_name'].iloc[0], df3['reward_model_name'].iloc[0], df4['reward_model_name'].iloc[0]])
# Reset the index for a cleaner look
all_stats.reset_index(inplace=True)
all_stats.rename(columns={'level_0': 'Model', 'level_1': 'Statistic'}, inplace=True)
all_stats.pivot(index='Model', columns='Statistic')
| モデル名 | 報酬タイプ | 最小値 | 25%分位数 | 中央値 | 75%分位数 | 最大値 | 平均 | 標準偏差 | データ数 |
|---|---|---|---|---|---|---|---|---|---|
| reward-model-deberta-v3-base | chosen | -7.035 | -4.209 | -3.121 | -1.981 | 4.317 | -3.080 | 1.586 | 160,800 |
| reward-model-deberta-v3-base | rejected | -7.139 | -4.279 | -3.210 | -2.100 | 3.876 | -3.173 | 1.552 | 160,800 |
| reward-model-deberta-v3-large | chosen | -7.106 | -3.670 | -2.353 | -1.141 | 5.589 | -2.358 | 1.854 | 160,800 |
| reward-model-deberta-v3-large | rejected | -7.201 | -3.789 | -2.534 | -1.380 | 5.404 | -2.531 | 1.775 | 160,800 |
| reward-model-deberta-v3-large-v2 | chosen | -8.320 | -4.070 | -3.135 | -2.007 | 2.636 | -3.035 | 1.488 | 160,800 |
| reward-model-deberta-v3-large-v2 | rejected | -8.334 | -4.305 | -3.495 | -2.426 | 2.558 | -3.369 | 1.465 | 160,800 |
| reward-model-electra-large-discriminator | chosen | -5.460 | -0.806 | -0.632 | -0.492 | 3.874 | -0.715 | 0.537 | 160,800 |
| reward-model-electra-large-discriminator | rejected | -5.452 | -0.813 | -0.633 | -0.489 | 4.094 | -0.724 | 0.556 | 160,800 |
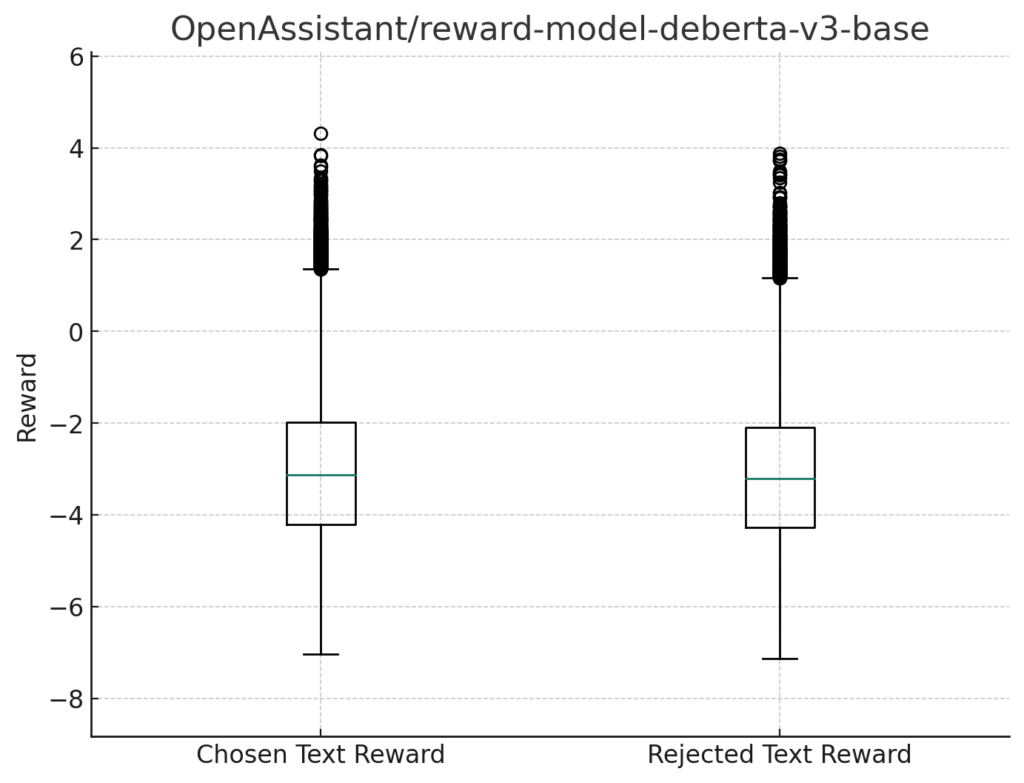
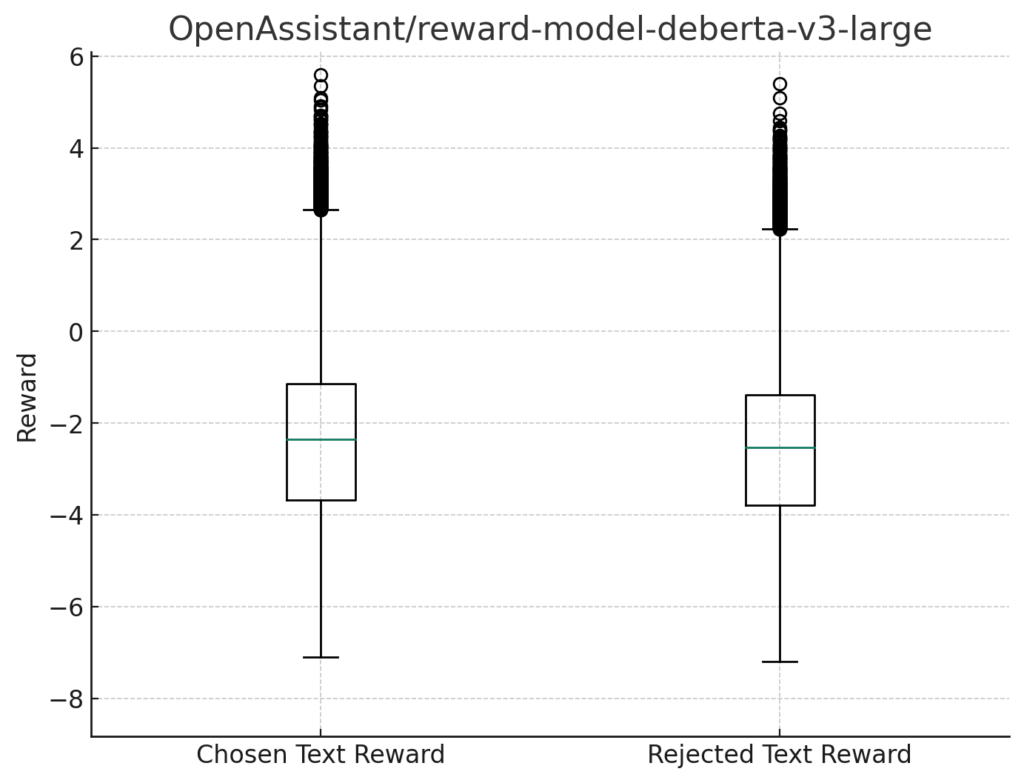
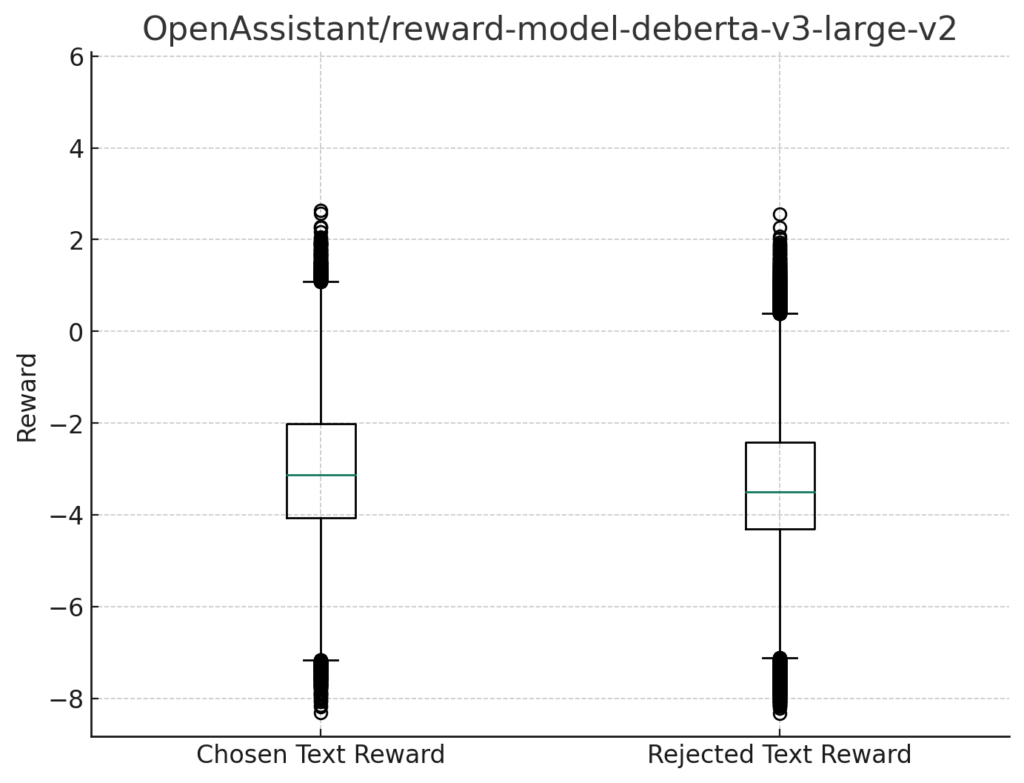
報酬の箱ひげ図
各モデルの報酬の分布を箱ひげ図(box plot)で描画し、これらの箱ひげ図を比較します。
箱ひげ図は、データの分布を視覚化するための効果的な手段であり、中央値、四分位数、外れ値などの重要な統計情報を一目で理解することができます。
箱ひげ図を描写するコード
# Function to plot box plots with fixed y-axis
def plot_boxplot_fixed_yaxis(df, title, y_min, y_max):
# Prepare data
data = [df['chosen_text_reward'], df['rejected_text_reward']]
plt.figure(figsize=(8, 6))
plt.boxplot(data)
plt.title(title)
plt.xticks([1, 2], ['Chosen Text Reward', 'Rejected Text Reward'])
plt.ylabel('Reward')
plt.ylim(y_min, y_max)
plt.show()
# Determine the y-axis limits
y_min = min(df1['chosen_text_reward'].min(), df1['rejected_text_reward'].min(),
df2['chosen_text_reward'].min(), df2['rejected_text_reward'].min(),
df3['chosen_text_reward'].min(), df3['rejected_text_reward'].min(),
df4['chosen_text_reward'].min(), df4['rejected_text_reward'].min()) - 0.5 # Adding some padding
y_max = max(df1['chosen_text_reward'].max(), df1['rejected_text_reward'].max(),
df2['chosen_text_reward'].max(), df2['rejected_text_reward'].max(),
df3['chosen_text_reward'].max(), df3['rejected_text_reward'].max(),
df4['chosen_text_reward'].max(), df4['rejected_text_reward'].max()) + 0.5 # Adding some padding
# Plot box plots for each sheet with fixed y-axis
for df in [df1, df2, df3, df4]:
model_name = df['reward_model_name'].iloc[0]
plot_boxplot_fixed_yaxis(df, model_name, y_min, y_max)
reward-model-deberta-v3-base
reward-model-deberta-v3-large
reward-model-deberta-v3-large-v2
reward-model-electra-large-discriminator
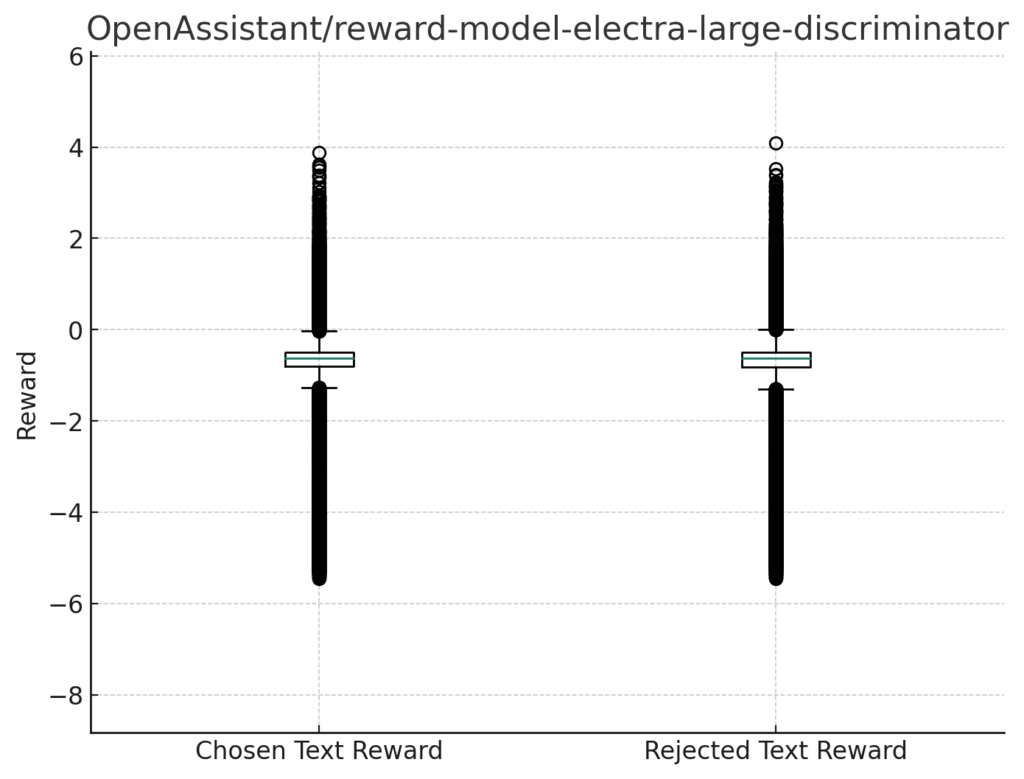
すべてのモデルにおいて、Chosen Text Rewardでさえ大半のデータを負の報酬を与えていることが分かります。
翻訳の精度などの問題も大いにあると思うので、ある意味報酬としては合っている可能性もあります。
chosenとrejectedの報酬の分布
各モデルについてchosenとrejectedの報酬の分布を見てみます。
横軸や縦軸に注意して下さい。
コードはこちら
import matplotlib.pyplot as plt
# Function to plot histograms
def plot_histograms(df, title):
plt.figure(figsize=(14, 6))
plt.hist(df['chosen_text_reward'], bins=100, alpha=0.5, label='Chosen Text Reward')
plt.hist(df['rejected_text_reward'], bins=100, alpha=0.5, label='Rejected Text Reward')
plt.title(title)
plt.xlabel('Reward')
plt.ylabel('Frequency')
plt.legend(loc='upper right')
plt.show()
# Plot histograms for each sheet
plot_histograms(df1, df1['reward_model_name'].iloc[0])
plot_histograms(df2, df2['reward_model_name'].iloc[0])
plot_histograms(df3, df3['reward_model_name'].iloc[0])
plot_histograms(df4, df4['reward_model_name'].iloc[0])
reward-model-deberta-v3-base
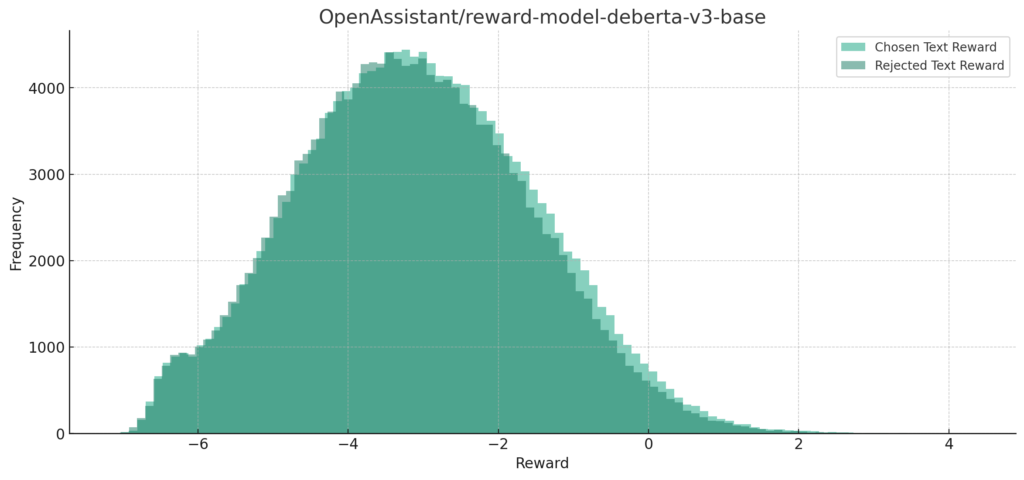
reward-model-deberta-v3-large
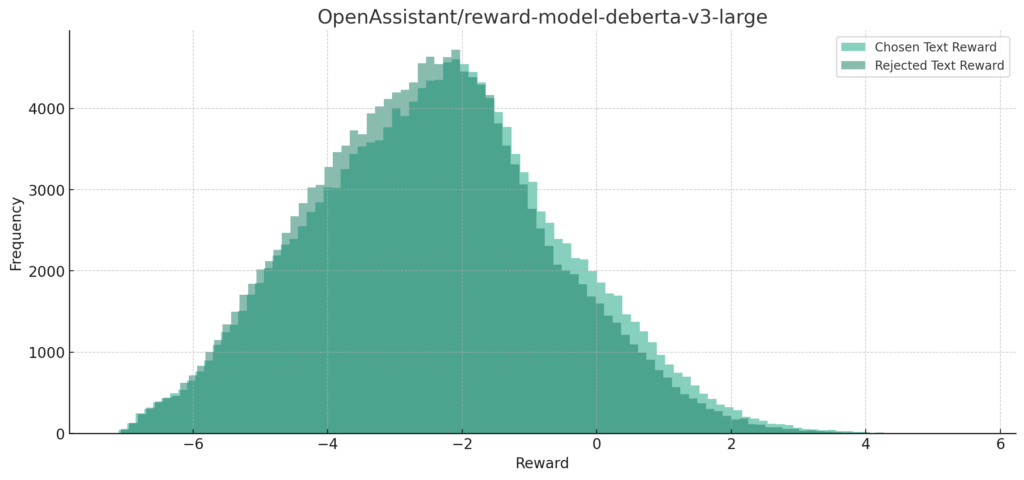
reward-model-deberta-v3-large-v2
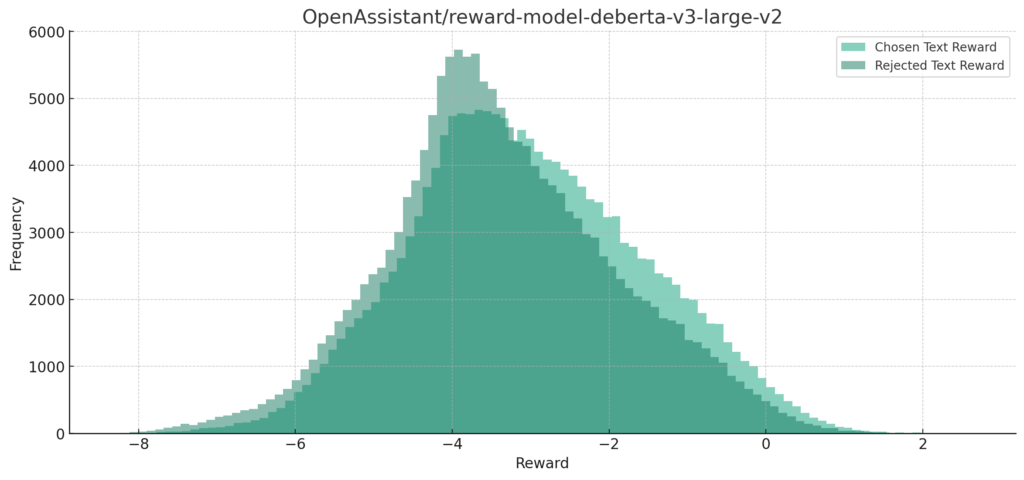
reward-model-electra-large-discriminator
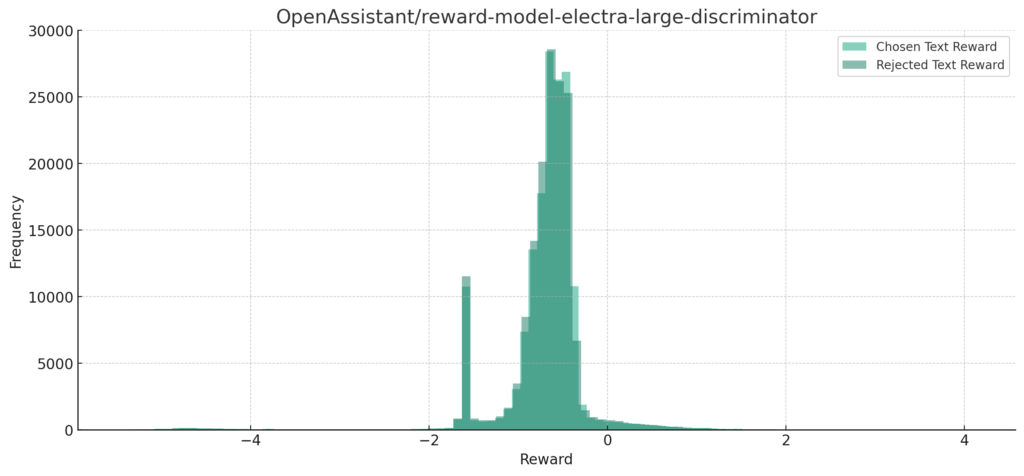
分布的にはchosen Text Rewardの大半が0以上になるのが理想的な感じだと思いますが、すべてのモデルで負の値に集まっていますね。
また、Chosen Text RewardとRejected Text Rewardで分布がほとんどが重なってしまっています。
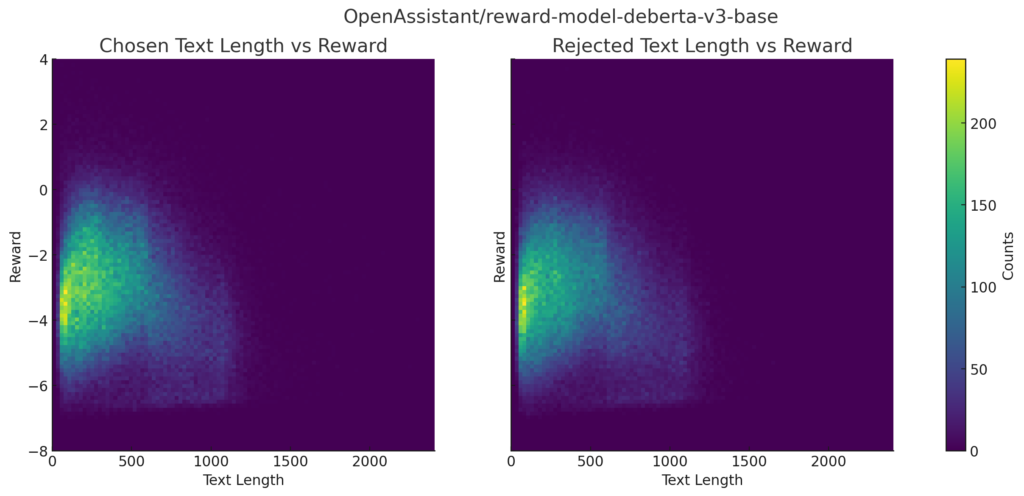
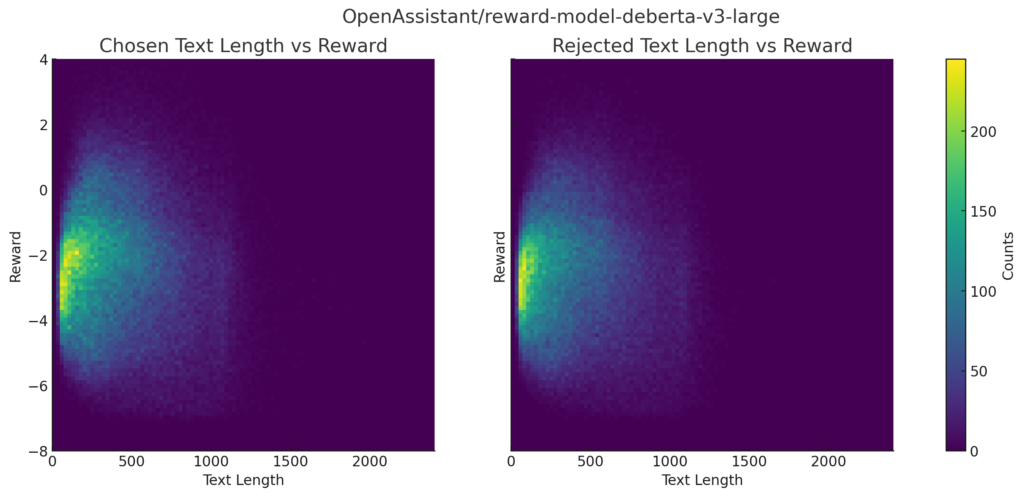
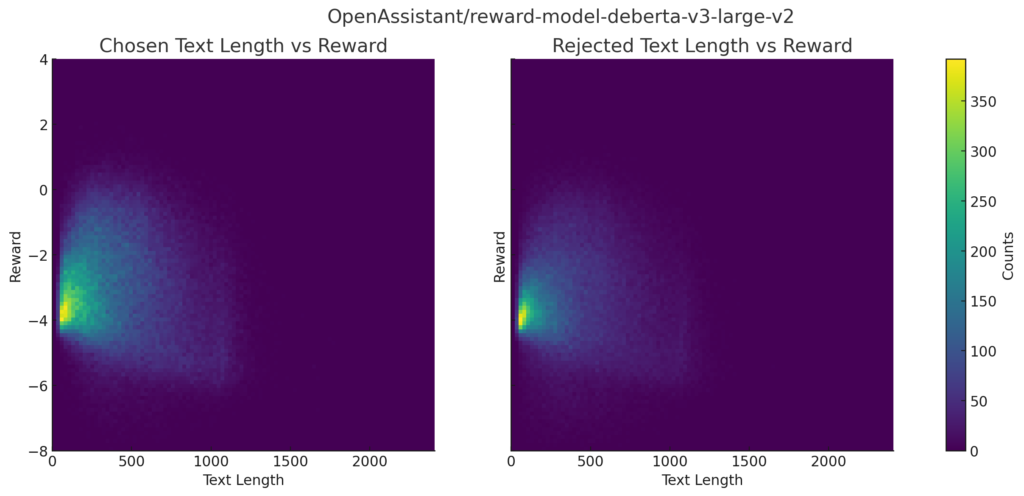
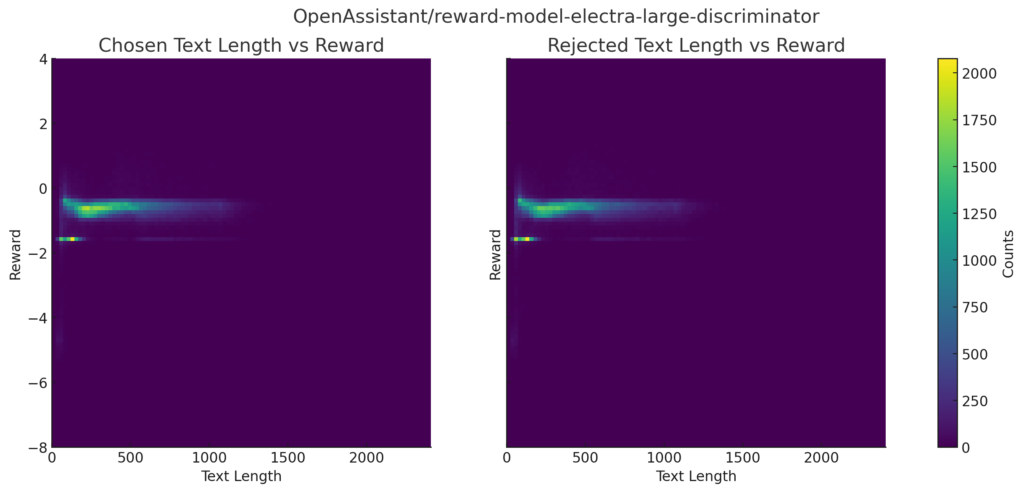
【おまけ】報酬とテキストの長さの分布
報酬とテキストの長さの分布です。
描写コード
# Extract the model names from the 'reward_model_name' column
model_names = [df1['reward_model_name'][0], df2['reward_model_name'][0],
df3['reward_model_name'][0], df4['reward_model_name'][0]]
# Plot 2D histograms for all models with increased resolution
plot_2d_hist_fixed_color_high_res(df1, df1, model_names[0])
plot_2d_hist_fixed_color_high_res(df2, df2, model_names[1])
plot_2d_hist_fixed_color_high_res(df3, df3, model_names[2])
plot_2d_hist_fixed_color_high_res(df4, df4, model_names[3])reward-model-deberta-v3-base
reward-model-deberta-v3-large
reward-model-deberta-v3-large-v2
reward-model-electra-large-discriminator
最後に
今回はRLHFで使える報酬モデルについて分析してみました。
やはり日本語の文章に適切な報酬を与えるなら日本語のデータで学習した報酬モデルが必要だと感じました。
今後は、それぞれの役割を持たせた報酬モデルを作るなど色々試したいと思います。

コメント