【DALL-E mini】AIによるテキスト→画像生成を実際に試してみた!スマホでも生成できる!

テキストから画像を生成する技術は、ここ数年でかなりの進歩を遂げました。
その中で、OpenAIがかなりの高精度でテキストから画像を生成することができるDALL-Eを発表しました。
現在は、DALL-E 2というより性能の良いモデルが発表されています。
今回試したDALL-E miniは、そんなすごいモデルをより小さくしたモデルになります。
小さいとはいうものの面白い画像が生成できるので、ぜひ遊んでみてください。
同じようにテキストから画像を生成するAIとして、「Dream by WOMBO」も面白いですよ。

最近は、「Midjourney」も話題になっています。

さらに話題の「Stable Diffusion」も試しています。

使い方
使い方は至ってシンプルです。
まずは、こちらをクリックしてください。
すると、次のようなページが出てきます。
そして、Runのボタンの左のエリアに生成したい画像の説明を記入します。
記入し終わったらRunのボタンを押して数十秒待つと、画像が9枚生成されます。
生成される画像について
今回試したような画像生成モデルには、社会的な偏見を増幅させるような画像を生成する可能性があります。
詳しくは、こちらのbiasをご覧ください。
簡単な日本語で画像生成
では、画像をいろいろと生成してみたので見ていきましょう!
「モデルは英語の説明でのみトレーニングされており、他の言語ではうまく機能しません」とこちらのLimitationsに書かれていますが、まずは、日本語を入力して画像を生成していきたいと思います。
ごはん
食べ物を生成してほしいと思ったので、「ごはん」とだけ入力してみました。
約20秒後に生成された画像がこちらです。
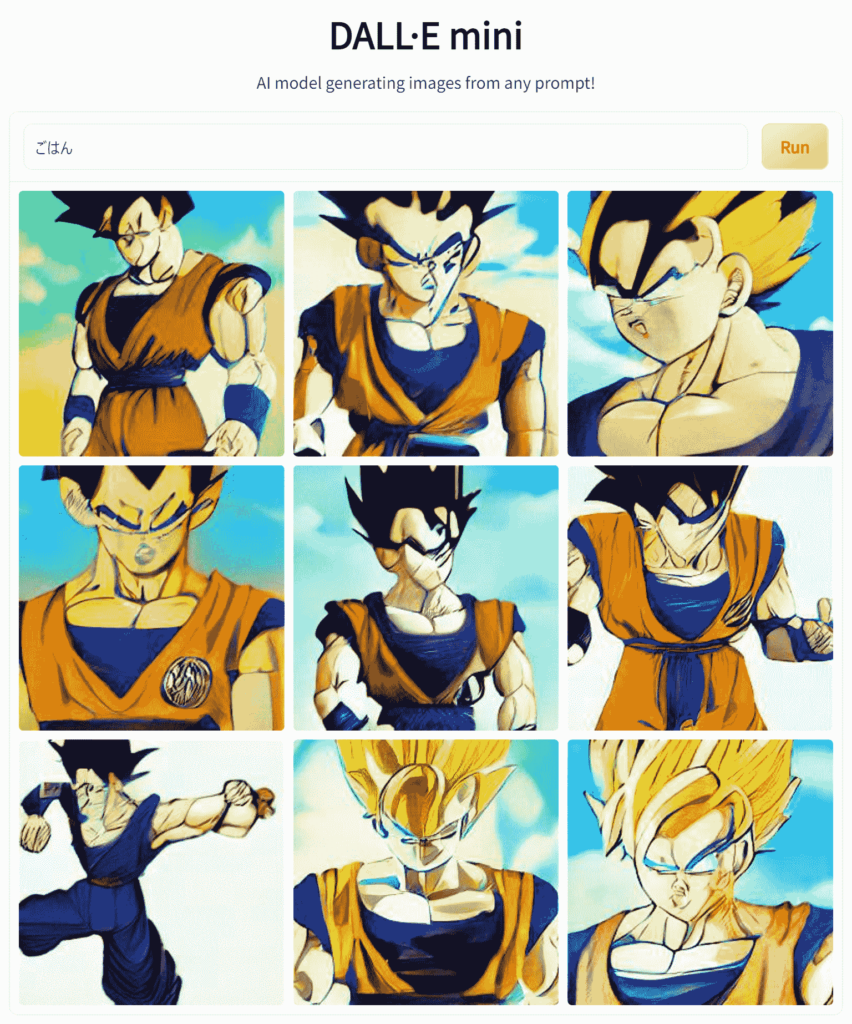
スーパーサイヤ人になってしまいました。
ならば、次は狙ってスーパーサイヤ人を呼び出してみます。
悟飯
ということで、「悟飯」と入力して生成された画像がこちらです。

あなたは誰ですか?
やはり日本語ではだめなのでしょうか?
スーパーサイヤ人
では、最後のあがきとして「スーパーサイヤ人」と入力してみます。
その結果がこちらです。

諦めました。
ご飯
最初にやりたかったことに戻ります。
「ご飯」と入力することで何か食べ物を生成してくれるはずです。

ご飯らしきものが4枚生成されていますね。
複雑な日本語で画像生成
では、もう少し複雑な説明を与えると、どのような画像を生成するのかを見ていきましょう。
宇宙服を着た馬
複雑?な日本語として「宇宙服を着た馬」を入力してみました。
結果は、下の画像になります。

想定とは全く違う画像になってしまいました。
やはり、日本語では限界があるということだと思います。
英語で画像生成
次に、英語で画像生成を試していきます。英語が苦手な方は、「DeepL」を使うといい感じに翻訳してくれます。
A horse wearing a space suit
日本語で試した時のリベンジとして、「A horse wearing a space suit」(宇宙服を着た馬)を試してみました。

めっちゃいいという感じではないですが、面白い画像なのは確かです。
A horse wearing a space suit watches a supernova explosion
続いて、この馬に超新星爆発を見てもらいましょう。
「A horse wearing a space suit watches a supernova explosion」(宇宙服を着た馬が超新星爆発を見る)を入力して生成した画像がこちらです。

壮大な印象を受けます。
何か物語が始まりそうな画像もありますね。
Artificial intelligence
AIにAIとは何かを聞くみたいで面白そうなので、「Artificial intelligence」と入力してみました。

人間が想像しがちな画像ですね。
Communityの面白いテキストで画像生成
こちらのCommunityから抜粋した面白いと思ったテキストを入力して画像生成してみました。
Apple VR/AR headset
Apple製のVR/AR ヘッドセットです。

かなりリアルですね。
Skeksis speaking before Congress on C-SPAN
C-SPANで行われた議会でのSkeksis氏のスピーチです。

場所とキャラクターを良く知っている人なら面白いかも?
最後に
今回は、画像生成において有名なDALL-Eの小型版を実際に利用しました。
日本語のテキストで生成した画像はあまり良くありませんでしたが、英語のテキストで生成した画像はminiという割にはテキストを画像で上手く表現できていたと思います。



コメント