【BLOOM】1760億パラメータを持つ多言語モデルの性能・使い方を調べてみた!

今回は、「BLOOM」という1760億ものパラメータをもつ多言語モデルの紹介です。
では、「BLOOM」について見ていきましょう。
BLOOMについて
「BLOOM」とは、産業規模の計算リソースを使用して大量のテキストデータを用いて学習した多言語モデルです。
人間が書いたテキストとほとんど区別できない46の自然言語と13のプログラミング言語の一貫したテキストを出力することができます。
また、GPT-3でも見られたような明示的に学習していないタスクについてもテキスト生成タスクとして投げかけることで、その実行を指示することができます。
これまでも超巨大な言語モデルは登場していましたが、特定の人にしか扱うことができないクローズドなものでした。その制約を取っ払うという意味において「BLOOM」はとてつもなく大きな存在であることは言えると思います。
まあ、それでも1760億パラメータを持つモデルを扱えるマシンは持っていない人の方が多数ですが…
対応言語(学習テキスト)
次に、対応言語についてみていきましょう。
学習テキストの中でそれぞれの言語がどれくらい入っているのかについては、後述するモデルのバージョンによって多少変動があります。
以下は、1760億パラメータを持つモデルについて書いています。
その他のバージョンについては、こちらからご覧ください。
- 英語(30.04%)
- 中国語-簡体字(16.20%)
- フランス語(12.9%)
- スペイン語(10.80%)
- プログラミング言語(10.80%)
- ポルトガル語(4.90%)
- アラビア語(4.60%)
- インド語族(4.40%)
- カタロニア語(1.10%)
- バスク語(0.15%)
- 中国語-繁体字(0.05%)
- ニジェール・コンゴ語(0.03%)
残念ながら日本語は含まれていません。
悲しいです。
プログラミング言語には、以下の言語が含まれます。
- Java
- PHP
- C++
- Python
- JavaScript
- C#
- Ruby
- Lua
- GO
- TypeScript
- C
- Scala
- Rust
インド語族とニジェール・コンゴ語族の詳細・それぞれのプログラミング言語のファイル数については、こちらをご覧ください。
利用可能なモデルのバージョン
同じデータセットに対して、いくつかのバージョンのモデルが学習されています。
BLOOMは以下のバージョンで利用可能です。
bloom-350mとbloom-750mは、完全に学習されていません。
学習が完了したモデルが必要な場合は、Bloom-1B3を使用しましょう。
簡易的に試す方法
まずは、スマホからでも利用できる方法を紹介します。
BLOOMに登録しよう
こちらからBLOOMのページ飛べるのでクリックしてください。
すると、ページの右側に次のような部分があると思います。
BLOOMを試すには、登録が必要になります。
登録は簡単なので、「register」をクリックして登録しましょう。
テキストを入力しよう
登録が終わったら、次のようになります。
「Your sentence here…」と書かれているエリアにテキストを入力しましょう。
入力したら「Compute」を押して数秒待つと、入力したテキストに続く文を生成してくれます。
実際に試してみた
では、実際にどういったことができるのかについて調べてみました。
日本語でテキストを入力
学習テキストには日本語は含まれていませんが、どうなるのか気になったので日本語で試してみました。
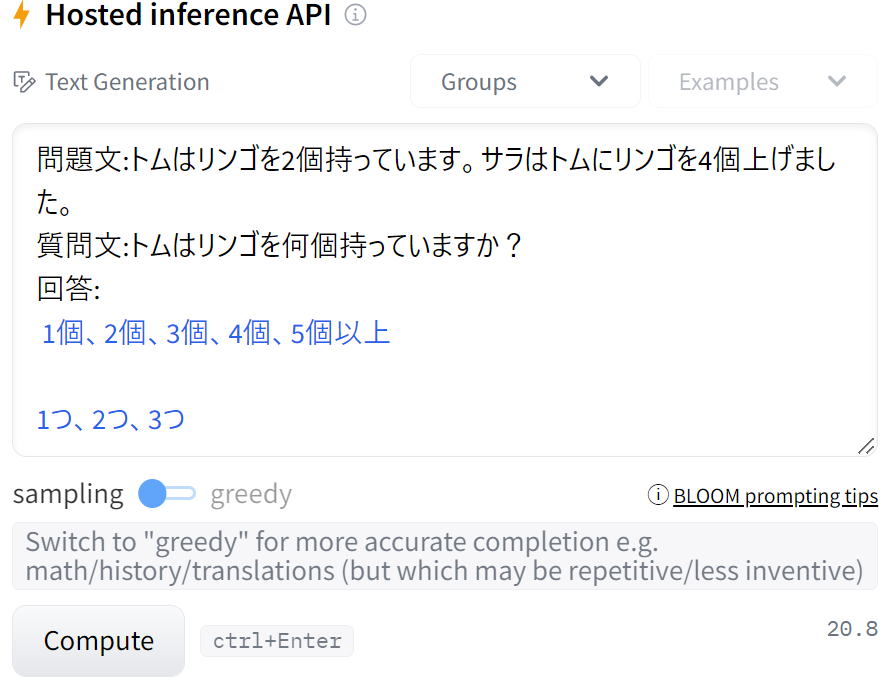
一応日本語は返してくれるみたいですね。
ですが、学習テキストに日本語は含まれていないので、BLOOMの性能を試すのは他の言語の方が良さそうです。
日本語のテキストを学習したモデルでは、rinna社が公開しているGPT-2があります。
こちらについても性能を試しています。

ということで、英語でいろいろと試してみたいと思います。
英語でテキストを入力
では、小学生で習うような問題を解いてもらうことにしましょう。
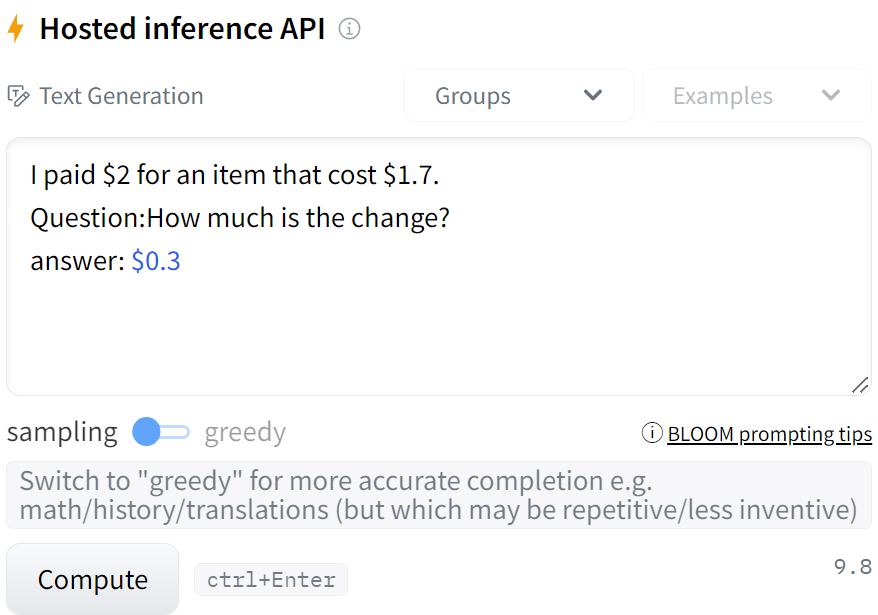
すごいですね。
より複雑な問題として、桁数を増やすとどうなるか試してみます。

計算式も書いてくれました。
学習データにこの形式のテキストがある可能性もありますが、それにしてもすごいですね。
次にpythonで書かれたプログラムをJavaに翻訳できるか試してみます。
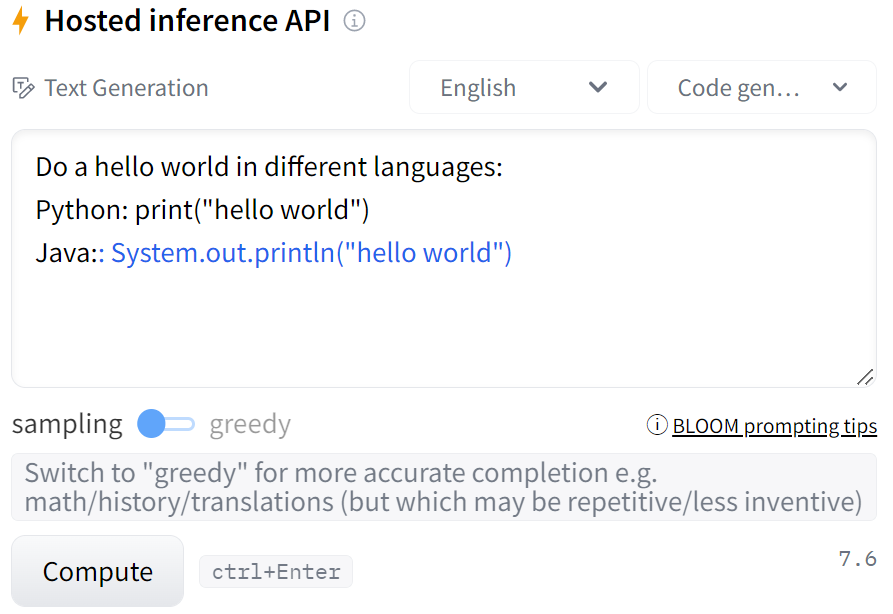
出来てますね!
最後に、宇宙がどうやって誕生したのかを聞いてみます。
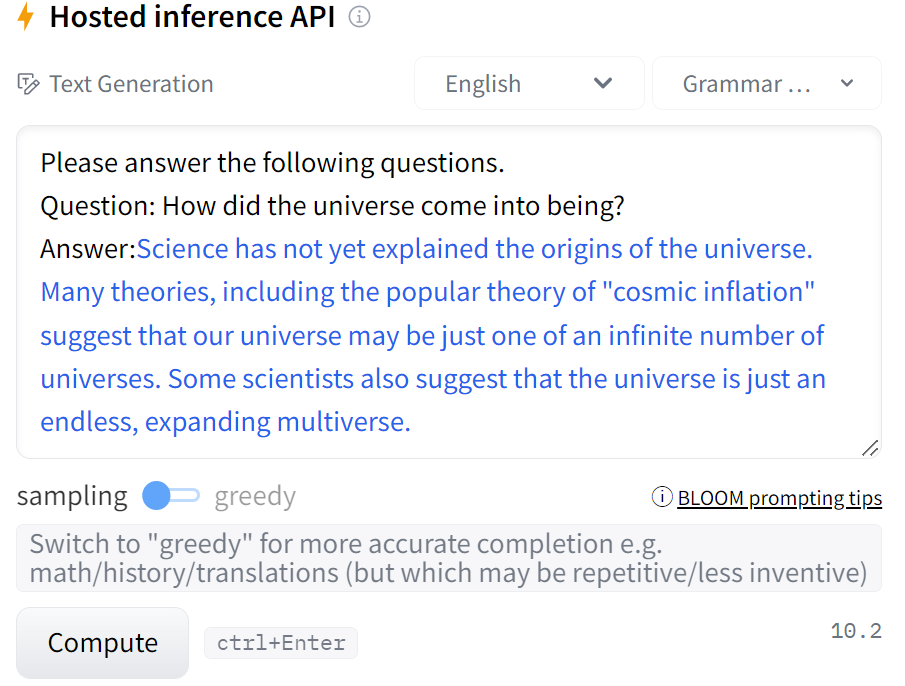
宇宙の起源は、科学ではまだ説明されていません。宇宙膨張説など多くの説があり、私たちの宇宙は無限にある宇宙の一つに過ぎないのではないかと言われています。また、宇宙は無限に広がる多元宇宙であると指摘する科学者もいます。
よくありそうな回答ですね。
Google Colaboratoryの無料枠を利用しよう
Pythonのコードを書いて動かす方法もあります。
マシンがない人は、Google Colaboratoryを利用しましょう。
無料でGPUを利用できます。
まずは、ランタイムをGPUにした後に以下のコードを実行しましょう。
# 必要なライブラリをインストール
!pip install transformers
!pip install accelerate次のコードで推論できます。
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
set_seed(3407)
# tokenizerの読み込み
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-350m")
# modelの読み込み
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-350m", device_map="auto", torch_dtype="auto")
# モデルに入力するテキスト
text = ""
input_ids = tokenizer(text, return_tensors="pt").to(0)
output = model.generate(**input_ids, max_length=50, top_k=0, temperature=0.7)
print(tokenizer.decode(output[0]))上の”bigscience/bloom-350m”を他のバージョンにするとモデルを変更できます。
textを変更することでいろいろと遊べます。
無料枠で利用できるモデルのバージョン
無料枠なので、マシンパワーには制限があります。
そこで、Google Colaboratoryの無料枠でどのモデルのバージョンなら使えるのかを調べてみました。
利用可能なモデルのバージョン
利用可能なモデルは以下の通りです。
- bloom-350m
- bloom-760m
- bloom-1b3
- bloom-2b5
利用可能かもしれないモデルのバージョン
使用可能なRAMを利用した後でセッションがクラッシュしました。
人によっては無料枠でも使えるかも?というモデルは以下の通りです。
- bloom-6b3
利用できないモデルのバージョン
利用できなかったモデルは以下の通りです。
- bloom (176B parameters)
さすがに最大サイズのモデルについては、無料枠で利用できなさそうですね。
最後に
今回は、1760億パラメータを持つモデル「BLOOM」を紹介しました。
今後、日本語テキストを学習した超巨大モデルも登場すると思います。
その時は、そのモデルについても調べてみます。
BLOOMは、Huggingfaceのおかげで簡単に使えるようになっています。


コメント